10 Oct 2023
Min Read
Seamless Data Flow: Integrating DeltaStream and Databricks
DeltaStream is powered by Apache Flink and processes streaming data from sources such as Kafka and Kinesis. The processed data can be used in downstream applications, materialized in a view, or written to data lakes and other analytical systems. Some common use cases of DeltaStream are latency sensitive applications where processed streaming data is needed in real time and data preparation use cases where users want to use a subset of the data contained within a stream. In this blog post, we are introducing Databricks as our latest integration with the DeltaStream platform. Now users can process data from their streaming data sources and write the results directly to Delta Lake.
Users are familiar with Apache Spark as a great batch solution for processing massive amounts of data. However, in real-time stream processing users are latency sensitive and that makes a real-time processing engine a perfect fit. In these cases, DeltaStream can be leveraged to continuously process streaming data and write to the Delta Lake, so that Delta Tables are always up to date and data is never late.
For applications such as those that alert on fraudulent activities, having both streaming and batch processing capabilities is useful. On the streaming side, DeltaStream can process data events in real time and generate alerts for fraudulent events when there are 3 or more withdrawals from the same bank account within 10 minutes for example. With our latest integration, these fraudulent events generated by DeltaStream can then be written into the Delta Lake and made available to Databricks for any further batch processing or historical analysis. For example, a data scientist may want to observe how many fraudulent events occurred in the past month, and with these alerts already available in their Delta Lake, they can easily do this analysis in the Databricks ecosystem.
Where does Databricks fit in with DeltaStream?
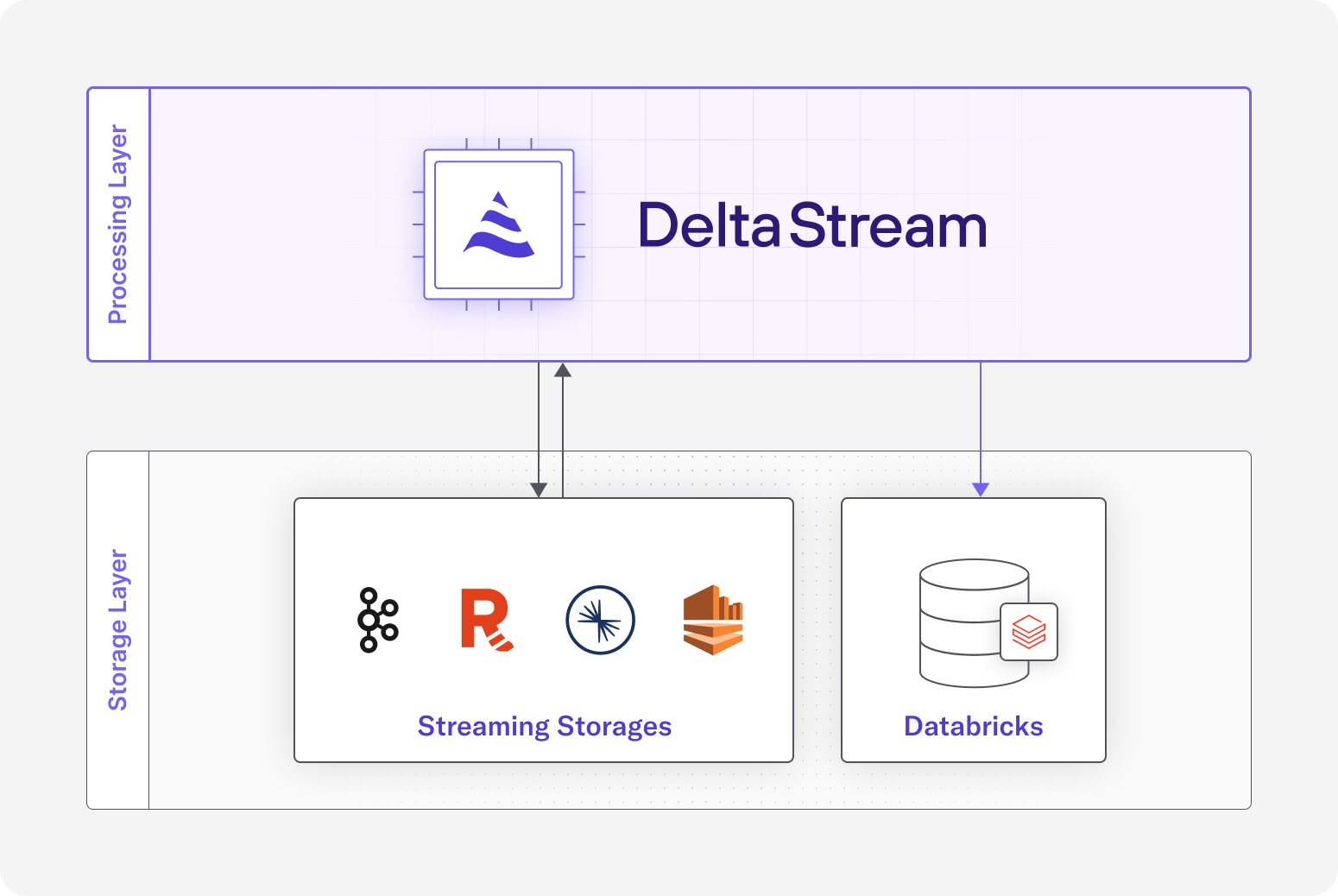
Databricks is a unified data and analytics platform. Databricks users can process, store, clean, share, and analyze their datasets to solve use cases ranging from business insights to machine learning. It has become an increasingly popular solution for data warehousing, but presents challenges with streaming data. For users with streaming data, they must first manage a connection to load their streaming data into Databricks, then perform ETL batch jobs to process and refine their data. For latency sensitive use cases there is a better way. With the new integration with Databricks, DeltaStream now sits in between users’ streaming data and Databricks. In the DeltaStream platform, users can transform and prepare their streaming data and write the results into Databricks with a single SQL query, meaning that any real-time transformations that need to take place on the streaming data can happen before the data is loaded into Databricks.
How DeltaStream integrates with Delta Lake
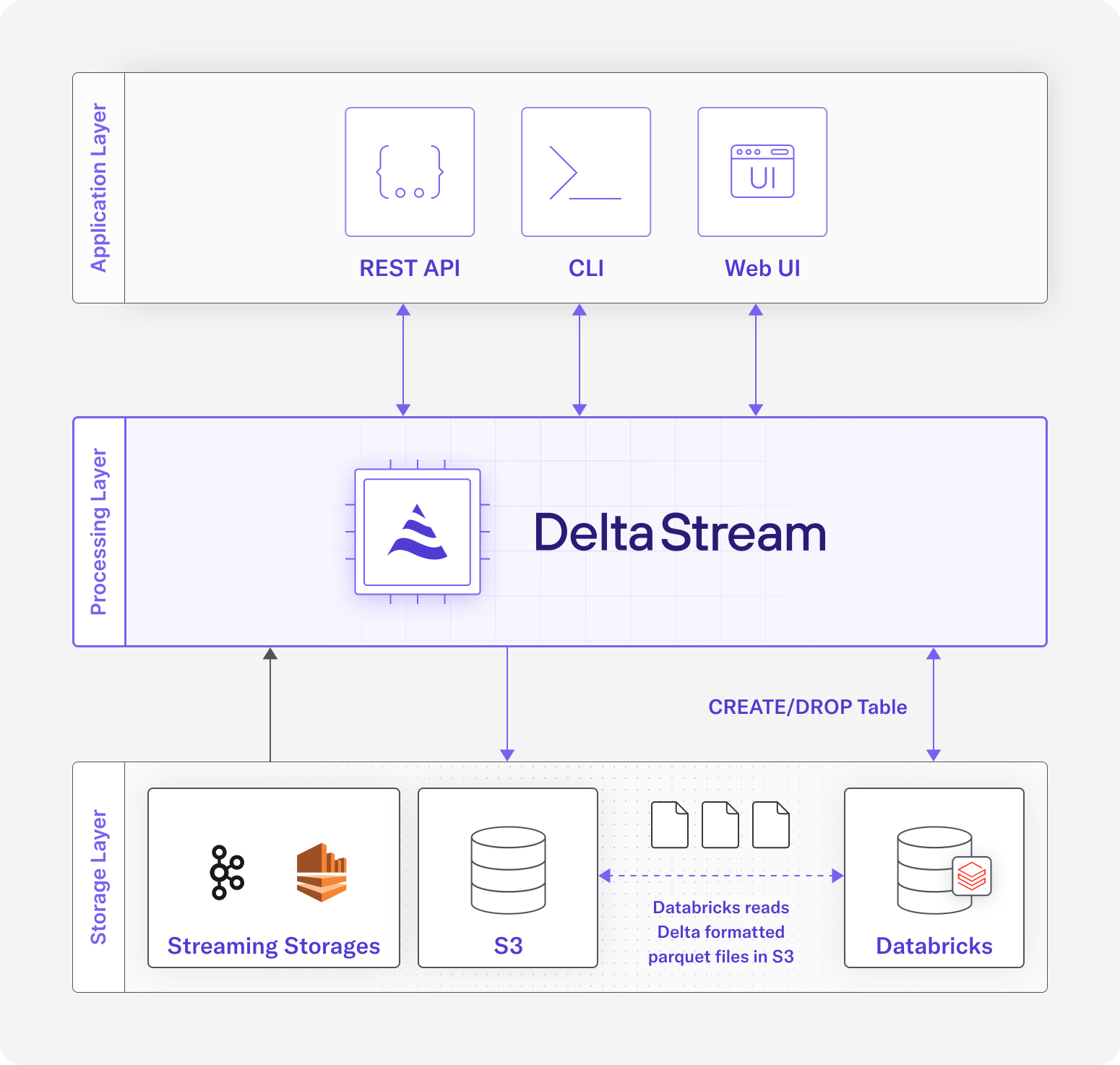
The Delta Lake is the storage layer that powers Databrick’s Lakehouse platform. To integrate with Databricks, DeltaStream needs to be able to write to Delta Lakes with the Delta Table format. Behind the scenes, DeltaStream uses Apache Flink as its compute engine. One of the advantages of using Apache Flink is the rich connector ecosystem that comes along with it, including a connector for the Delta Lake. Using the Delta sink connector, we were able to easily integrate our platform with Databricks.
The figure above displays the architecture at a high level. The user, interacting with DeltaStream’s CLI or Web UI, can issue a CREATE TABLE AS SELECT SQL query which the DeltaStream platform receives. DeltaStream will then perform validations and create a Databricks Table in the user’s Databricks workspace, using an associated S3 Delta Lake as the external location for the Table. A continuous DeltaStream query is then launched to perform the SQL computations. This continuous query will read from one of DeltaStream’s accepted sources, such as a Kafka topic, do any necessary transformations, and produce the results in Delta format to the AWS S3 account that is associated with the user’s Databricks workspace. At this point, the continuous query is constantly updating the user’s Delta Lake as records are arriving in the source, keeping the user’s Databricks Table up to date with the latest records. Users can also issue commands in DeltaStream to interact with Databricks such as listing, creating, or dropping Databricks Catalogs, Schemas and Tables. Users can also print their Databricks Table to view the rows.
Use Case: Loading data into Databricks
Let’s walk through an example use case to show off how easy it is to work with Databricks in DeltaStream. Suppose you have a Kafka topic which contains logging data from your stage environments and you want to load the data into Databricks. In this example, you’ll see how you can have an end-to-end solution to solve this use-case using DeltaStream in minutes.
Adding Databricks as a Store
Like Kafka and Kinesis, Databricks would be considered a Store in DeltaStream. The first step in starting the integration is to create the Databricks Store in your DeltaStream organization. The store can be created with the following SQL statement:
After adding the Store, you can interact with the Databricks unity catalog to perform commands such as create, describe, list, and drop.
CTAS Query
After adding your Databricks workspace as a Store in DeltaStream, you can use it to write CREATE TABLE AS SELECT queries (CTAS). These queries create DeltaStream Table Relations by selecting columns from one or multiple source Relations. In this example, let’s assume we already have a Stream of data called “my_logs” which is defined by the following DDL:
In DeltaStream, a CTAS query to only produce records in the “stage” environment would look like the following:
Validating results
After running this CTAS query, a new Databricks Table will be created with the fully qualified path of cat1.sch1.stage_logs. You can confirm this by describing and printing the Table Entity which will describe the underlying Databricks Table:
If you log into your Databricks workspace, you’ll also find the same information there.
The backing storage for the newly created table will be in S3 in the directory s3://some_bucket/stage_logs. You can validate that the data is arriving in S3 by checking in your AWS console, or from DeltaStream you can also validate that new data is arriving by issuing the PRINT command above.
Get Started with DeltaStream and Databricks
Databricks has provided an incredible platform for data engineers, making it simple and intuitive to manage and process data in your data lake or data warehouse. With DeltaStream’s new Databricks integration, we aim to make it easier for DeltaStream users and Databricks users to use both platforms where they shine and to provide a more complete user experience for streaming and non-streaming use-cases. We’re extremely excited to share this new integration. If you have any questions or want to try it out, reach out to us or try DeltaStream’s free trial!




