24 Jan 2024
Min Read
The Importance of Data Unification in Real-Time Stream Processing
In our previous blog post, Streaming Data Governance in DeltaStream, we discussed what Data Governance is, why it’s important, and how it works hand-in-hand with Data Unification in the context of real-time streaming data. In this blog, we’ll dive deeper into the concept of Data Unification.
What is Data Unification and why is it Important?
Stream processing solutions have relied on connecting directly to streaming storage systems, such as Apache Kafka and RedPanda, and running transformations on a series of topics. For the stream processing user, this requires an understanding of where and how the data (i.e. topics) are stored. An ops team would then need to authorize access to these data assets. The current stream processing approach is similar to running individual Spark jobs as opposed to using a platform such as Databricks.
The fundamental problems with this approach include the following:
- Access to streaming storage is limited to a small number of individuals due to complex and disjointed permissioning.
- Data analysts are required to understand which data storage systems and which topics contain the data needed for analysis.
- Stream processing workloads are created in silos by different teams. It’s very common for teams to be running their own Flink or other stream processing workloads.
- Reusing and sharing new data streams and data assets is difficult without a central platform that enables collaboration.
Data Unification for stream processing is needed to provide an organizational layer on top of the streaming stores that provide a complete view of streaming, relational and other data stores. Once a unified view is created, it unlocks the ability to seamlessly govern, access, and run stream processing workloads across an organization's data footprint.
The Current Data Landscape
The technologies that make up the current landscape of real-time streaming data were not built with Data Unification in mind. This isn’t a criticism of these technologies, as they have enabled real-time data products and solve complex distributed systems problems, but more of a statement to point out what’s been missing in the streaming data landscape.
Let’s consider Apache Kafka, which is currently the most popular streaming storage system. Topics are the organizational objects in Kafka that hold data events, and these topics are stored in clusters. Access to these topics is granted through Access Control Lists (ACLs). In most cases, organizations with real-time data will have multiple Kafka clusters or utilize a combination of streaming storage solutions, including RedPanda, Kinesis, and Apache Pulsar. Performing streaming analytics on these data sources requires users to work directly with the storage system APIs or use a stream processing framework, such as Apache Flink. This setup has 3 problems for Data Unification:
- Managing access control through ACLs is cumbersome and error prone. Access must be given per user, per topic. As the number of users and the number of topics grow, these lists can easily become unmanageable, resulting in security risks. Also, ACLs can’t be applied across multiple Kafka clusters, so access control operations are still siloed to the individual clusters or systems.
- Organization of data assets (topics) is flat. Without any namespacing capabilities, there is no way to organize or categorize topics. A flat namespace results in challenges with data discovery and data governance.
- Connecting directly to source/sink topics for each stream processing job is redundant and error prone. Writing stream processing applications that interact directly with the storage layer results in a large overhead to configure/maintain permissions. This can easily lead to mistakes in providing the wrong data access, resulting in organizations limiting the set of users that have access to data assets.
In the batch world, products like Databricks and Snowflake address these exact issues. Let’s consider Databricks for example. Databricks’s Unity Catalog provides a hierarchical namespace to Databricks Tables, such that each Table exists within a Catalog and Schema. While the Table is backed by parquet files existing in some S3 location (in the case of using Databricks on AWS), the logical representation of the Table in the Unity Catalog can be namespaced into any Catalog and Schema. This is very similar to the organizational structure of relational databases. Another similarity to relational databases is Databricks’s support of RBAC on their Unity Catalog. A particular Databricks user or team can be authorized access to a Catalog, Schema, or Table. Databricks also allows users to define SQL queries for data processing, which utilizes Apache Spark behind the scenes. As a result of having a Unity Catalog to view all of a user’s Tables, when a user writes such SQL queries, the queries can simply source from or write to Tables in the Unity Catalog. By operating at this logical abstraction layer with the Unity Catalog, the burden of obtaining S3 access, setting up connectivity to S3, and interacting directly with the storage layer is eliminated for users.
When compared to a data streaming system like Kafka, it becomes clear that Kafka is more akin to a physical storage system than a platform like Databricks, which offers products built on top of the storage layer. What is missing in real-time data stream processing is a solution that builds on top of streaming storage systems, such as Kafka and Kinesis, and allows users to organize and represent their streaming data in a single unified data catalog.
DeltaStream as the platform for Streaming Data Unification
DeltaStream is a complete stream processing platform to Unify, Process, and Govern all of your streaming data. Taking after the examples in the batch world, DeltaStream utilizes concepts such as data catalogs and RBAC to provide a unified and governed data platform for real-time streaming data.
DeltaStream can connect to any data streaming storage system, including Kafka, RedPanda, and Kinesis, as well as relational databases, such as PostgreSQL. A Store in DeltaStream is used to define the connection to these storage systems. Once a Store has been defined, users can create Relations that are backed by the data objects in each Store. For example, a Relation can be created that is backed by a topic in a Kafka Store. These Relations are organized into DeltaStream’s Streaming Catalog. The Streaming Catalog has two levels of namespacing in the form of Databases and Schemas. Relations can belong to any Database and Schema, and Relations from different storage systems can be co-located into the same Database and Schema. Since Relations in the Streaming Catalog can be backed by data in different storage systems, the Streaming Catalog becomes the singular unified place to view and interact with all of this data.
With a Streaming Catalog, DeltaStream users can write queries which read and write to Relations in the Streaming Catalog. Access to the Streaming Catalog is managed through a robust RBAC model that enables privileges only to the data a user or team needs. With RBAC, users can easily and securely share their data assets. By writing DeltaStream queries using Relations, users can simply focus on their business logic as opposed to dealing with the underlying storage layer connectivity.
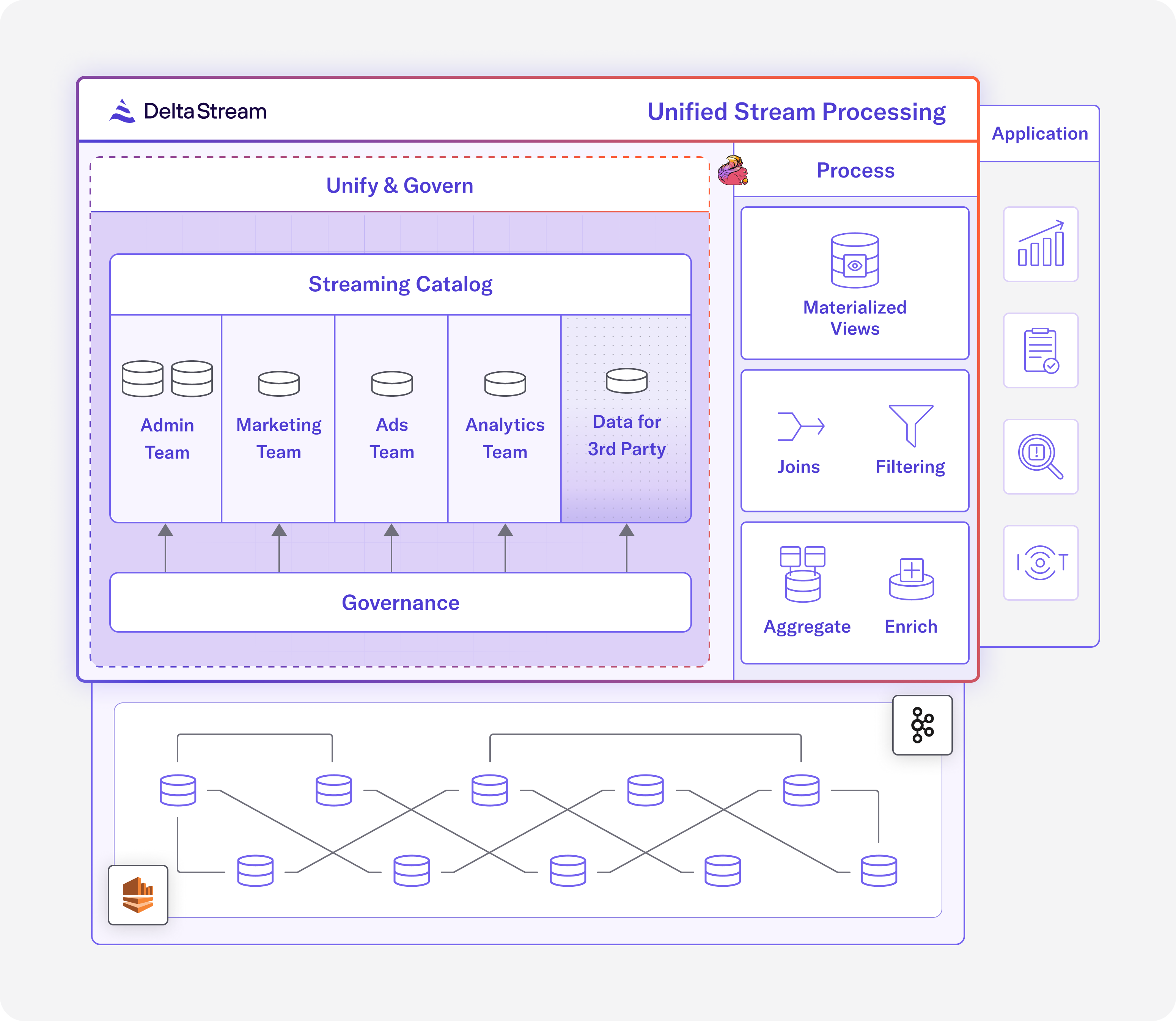
Overview of DeltaStream’s Streaming Catalog
Bring Data Unification to your Organization
In this post, we covered what Data Unification is and why it is important in the context of streaming data and stream processing. The part of Data Unification that often gets overlooked is having a unified view in the form of a data catalog. With a unified data catalog, Data Governance and data processing features built on this catalog become simpler and more intuitive to use. This is exactly why DeltaStream not only connects to different data storage systems, but also provides a Streaming Catalog to provide this unified view of data to users.
If you want to learn more about DeltaStream, reach out to us and schedule a demo.