11 Mar 2025
Min Read
Real-time Anomaly Detection with Sensor Data
Real-time sensor data monitoring is critical for industries ranging from manufacturing to IoT-enabled vehicle sensors for transport. Identifying anomalies, unexpected deviations that could signal equipment failure, environmental hazards, or system inefficiencies, becomes a key challenge when dealing with a stream of sensor readings flowing through a Kafka topic. This blog dives into the process of performing anomaly detection on a set of sensors publishing to a Kafka topic, guiding you through the steps to harness streaming data, apply detection techniques, and ensure timely insights. Whether you’re a data engineer or a curious developer, you’ll discover practical methods to spot the unusual in the constant hum of sensor activity.
Use Case: Missing Data as an Anomaly
For our scenario, we will work with 100 sensors that send a heartbeat every 5 minutes. The sensor is considered down if a heartbeat isn’t detected after 15 minutes. There are two scenarios this leads to: either the sensor is faulty and is sending heartbeats after the window, or it stops sending a heartbeat entirely. To simulate this data, I wrote a Python program with the following parameters:
- 100 sensors comprised of:
- UUID as a sensor ID
- Unix epoch timestamp
- Generate sensor records for 100 days starting from November 1, 2024
- Each sensor will start at random times over 48 hours from the start date
- 10% of the sensors will fail to generate a timestamp for a random amount of time between 15 and 120 minutes on a random number of days
- 2% of the sensors will stop sending a timestamp between 15 and 60 days from the first timestamp.
Here is the Python code if you want to play with it yourself in a free DeltaStream trial; you just need a Kafka cluster of your own available:
Our resulting JSON file looks like this:
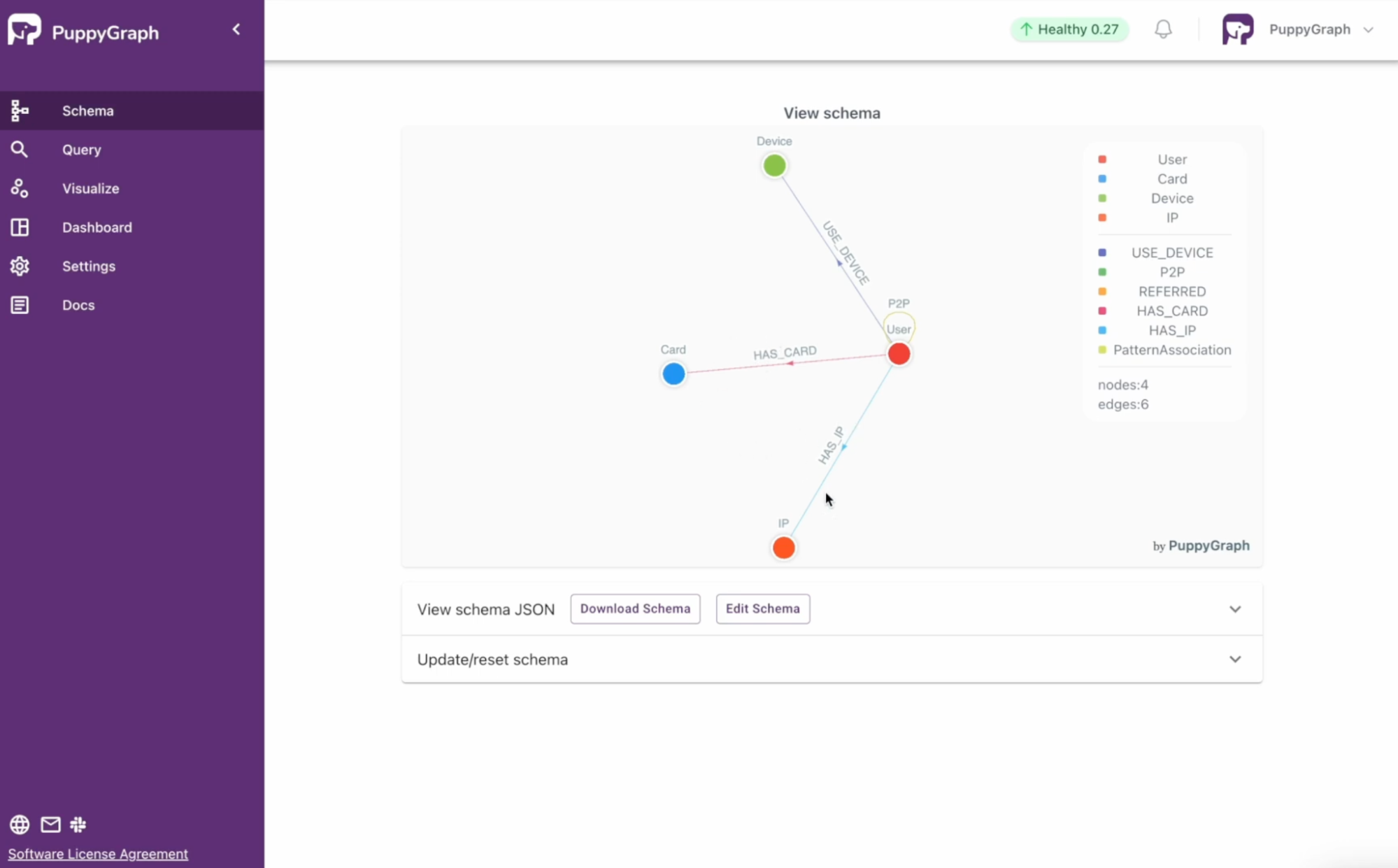
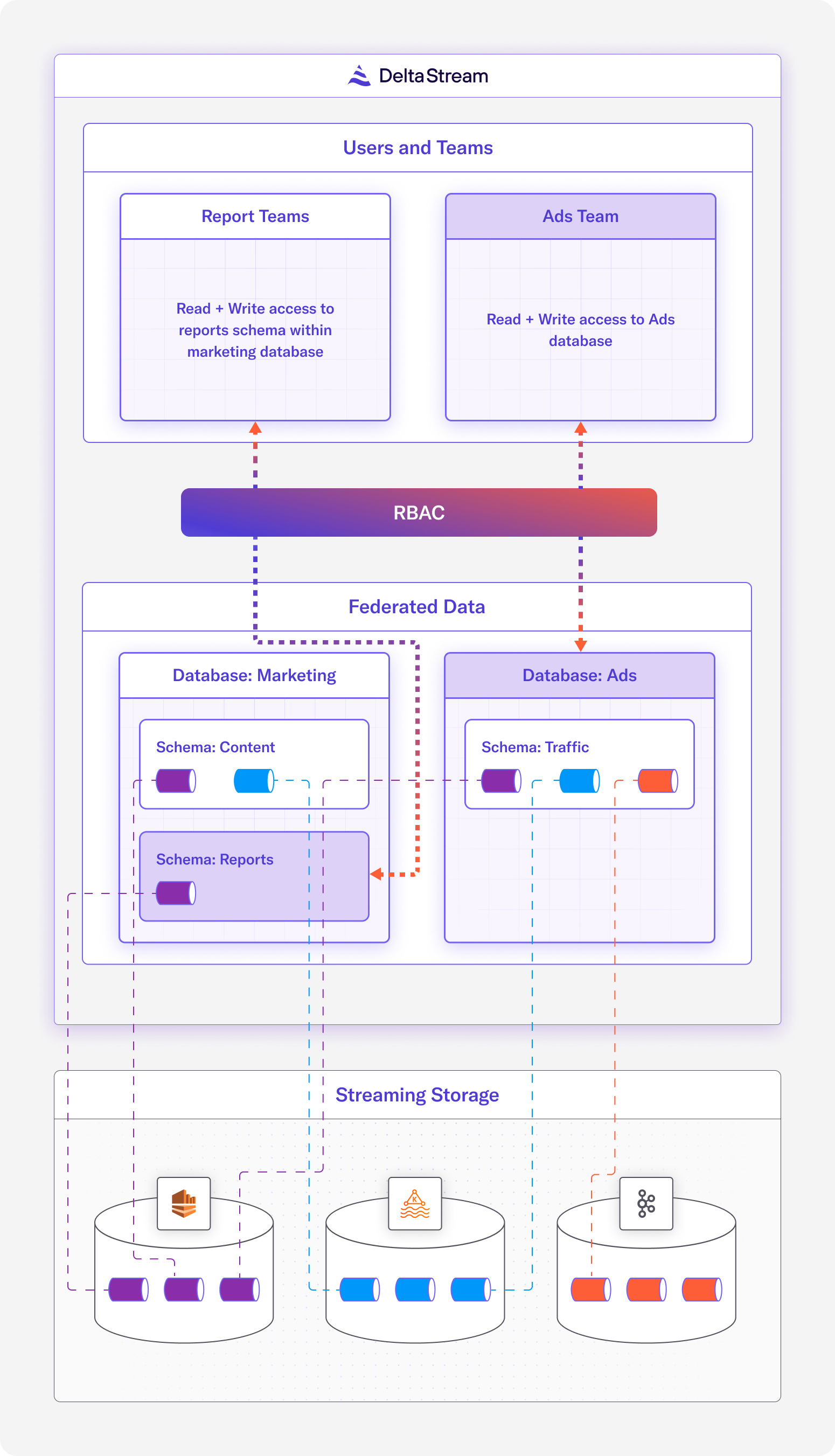
Solution: Detecting failed Sensors
All of the SELECT statements are displayed in the following screenshot, as well as some of the results of glitching sensors and the number of minutes they failed to send their heartbeat.
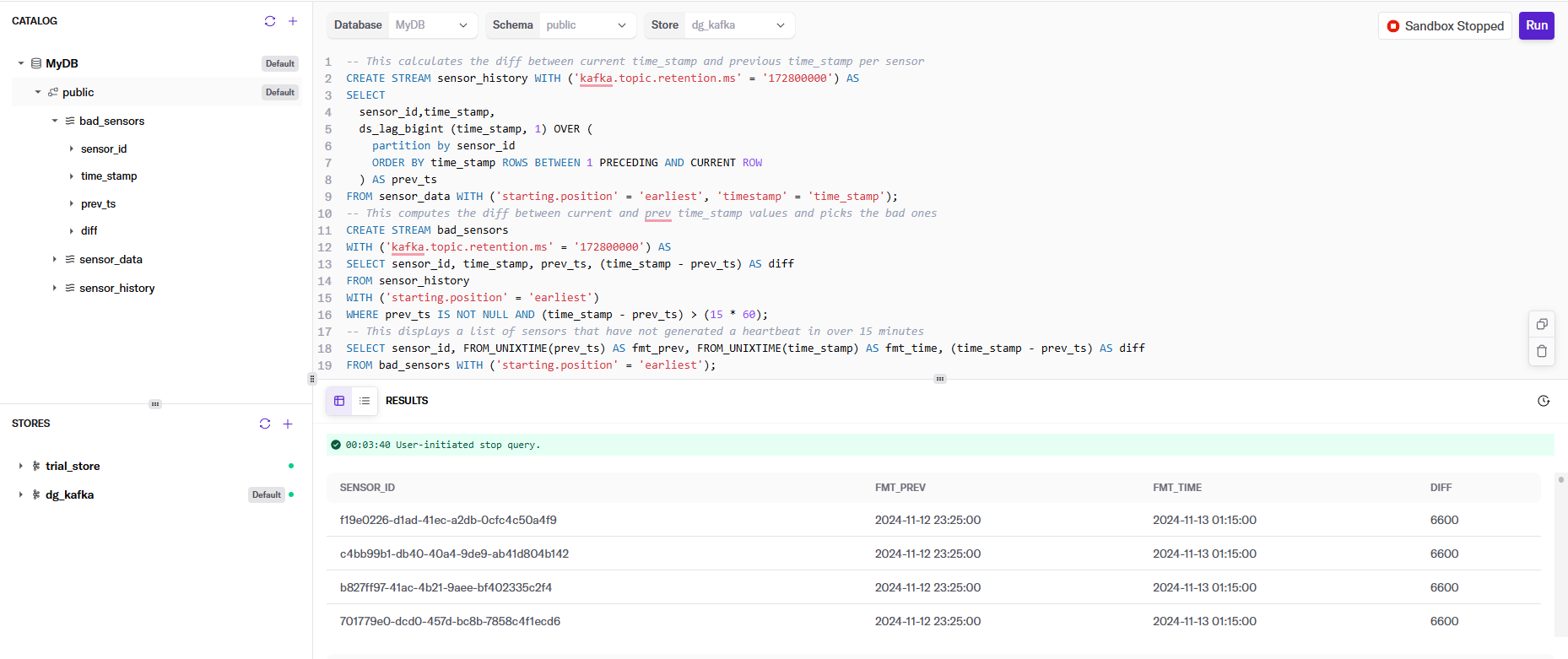
Let’s break down each of the statements and explain what we’re doing:
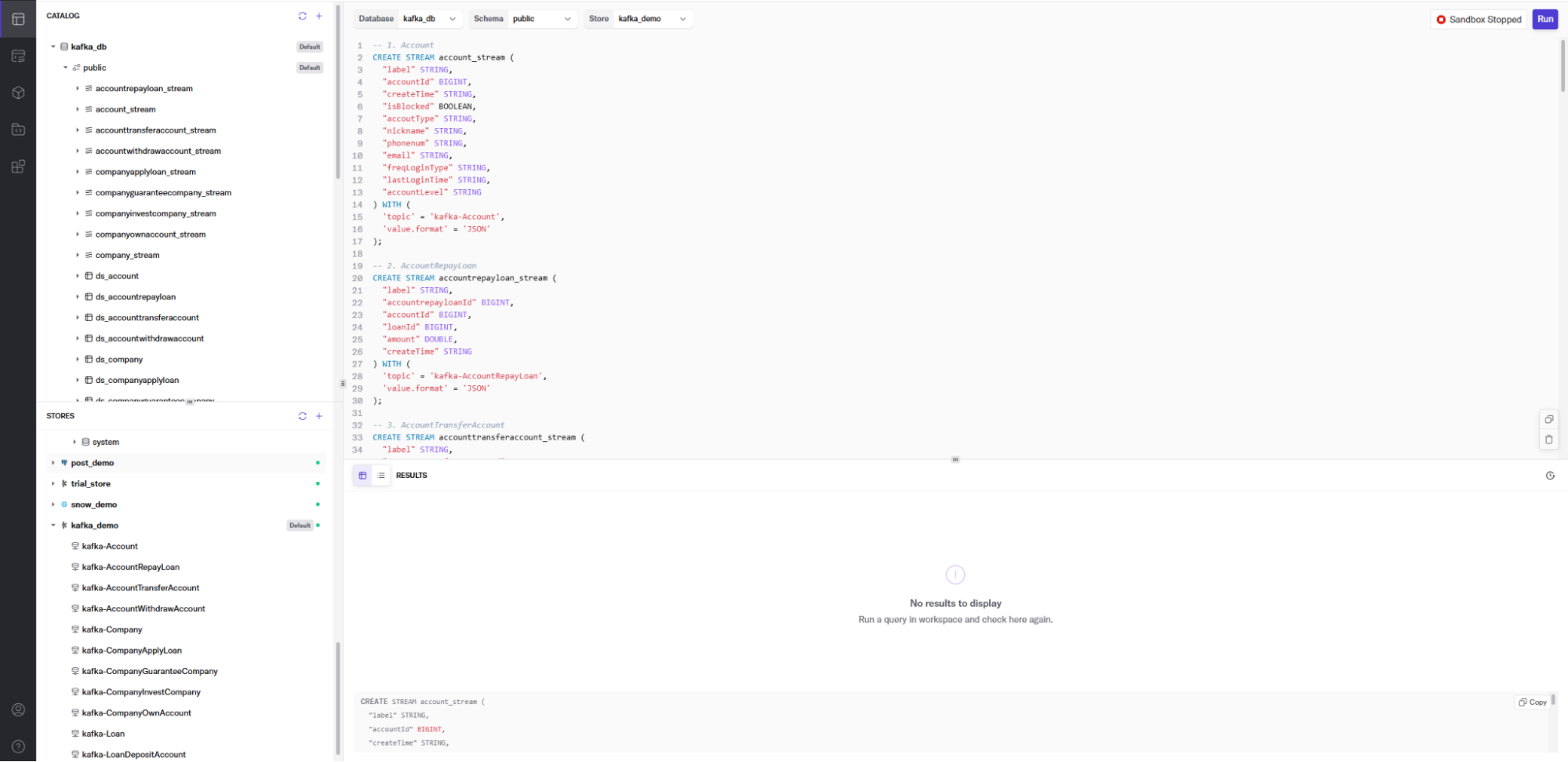
This first statement creates a DeltaStream Object of type STREAM that defines the layout of the sensor_data topic in our Kafka cluster. This gives us an entity that we can perform actions on against the topic.
This part has the secret sauce to making this work: the ds_lag_bigint function. It is a built-in function to access the value of a column from a previous row within the same relation. This is particularly useful for scenarios where you need to compare or compute differences between rows. In our case, we use it to determine the time interval between consecutive sensor events. The function requires specifying the column from which to retrieve values and the number of rows from which to look back. For example, ds_lag_bigint(time_stamp, 1) returns the time_stamp from the previous row, allowing us to calculate the time difference between consecutive sensor readings and thus determine if the difference is outside our acceptable bound of 15 minutes.
Other than that, we’re creating the stream topic with a retention of 72 hours (in milliseconds) to ensure the data lasts long enough to run my tests. Finally, the FROM clause forces the SELECT to read from the beginning of the topic, and what field is the timestamp.
Next, we create a new Kafka Topic, bad_sensors, for any record in sensor_history with two timestamps greater than 15 minutes. This will be our list of sensors with anomalies that need to be researched. If they go online and offline outside of our acceptable range, they are likely failing, or something else needs to be investigated.
Finally, let’s take a look at the data in bad_sensors. This formats out the current and previous heartbeat timestamps and the difference between them in minutes.
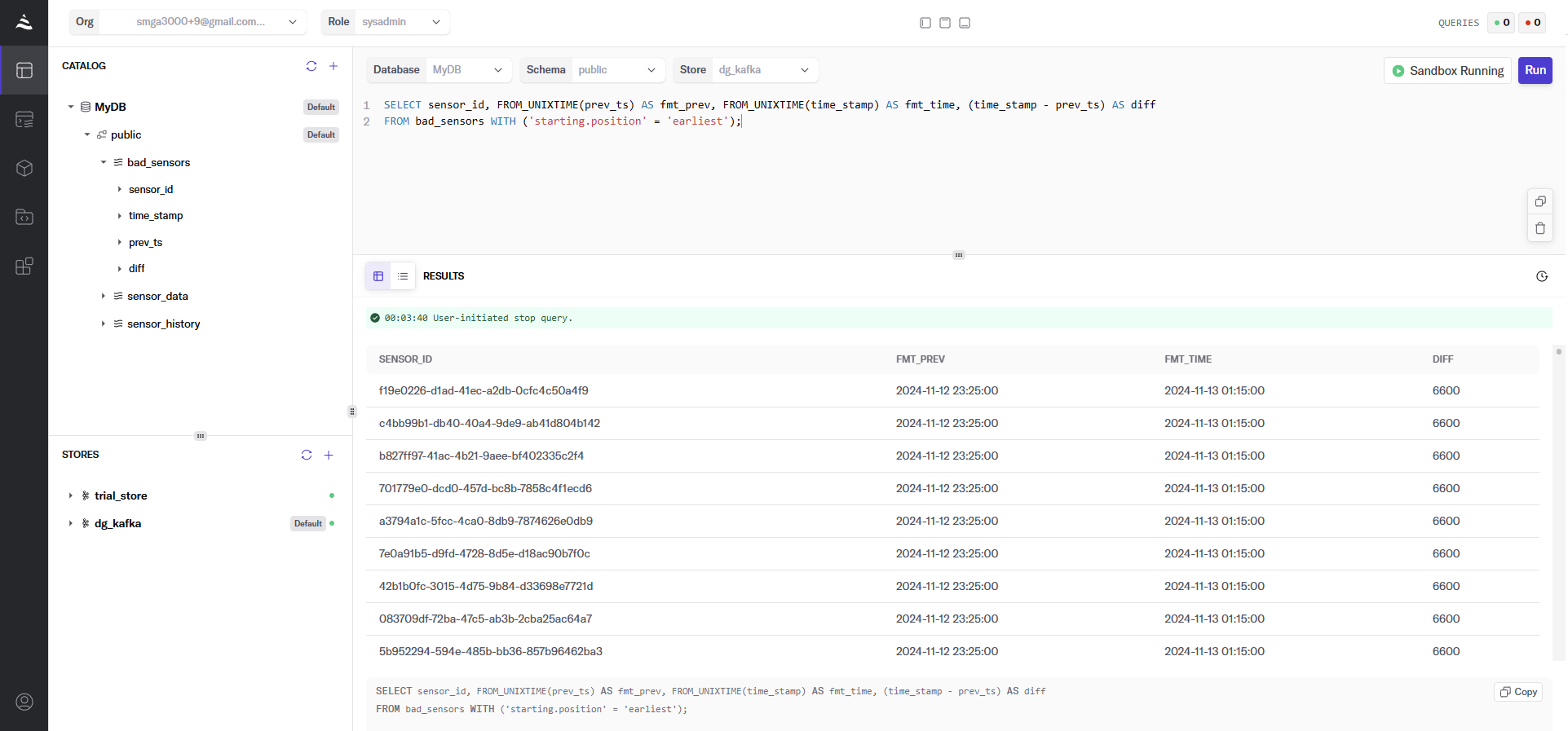
In a production environment, it would make sense for the bad_sensors data to be fed into a location that populates a dashboard where decisions can be made in near real-time. This could be something like Iceberg, Clickhouse, Databricks, Snowflake, or whatever you use.
Summary
This blog explores anomaly detection for real-time sensor data on a Kafka topic, using a 100-sensor setup with heartbeats every 5 minutes. We define anomalies as misses exceeding 15 minutes, simulate 100 days of data with Python, and apply DeltaStream to process it, racking history, calculating gaps with ds_lag_bigint, and pinpointing failures via SQL. This approach is streamlined for engineers and easily adaptable to production dashboards.