09 Jan 2024
Min Read
Bundle Queries with Applications by DeltaStream
Stream processing has turned into an essential part of modern data management solutions. It provides real-time insights which enable organizations to make informed decisions in a timely manner. Stream processing workloads are often complex to write and expensive to run. This is due to the high volumes of data that are constantly flowing into these workloads and the need for the results to be produced with minimal delay.
In the data streaming world, it’s common to think about your stream processing workload as pipelines. For instance, you may have a stream processing job ingest from one data stream, process the data, then write the results to another data stream. Then, another query will ingest the results from the first query, do further processing, and write another set of results to a third stream. Depending on the use case, this pattern of reading, processing, and writing continues until eventually you end up with the desired set of data. However, these intermediate streams may not be needed for anything other than being ingested by the next query in the pipeline. Reading, storing, and writing these intermediate results costs money in the form of network I/O and storage. For SQL-based stream processing platforms, one solution is to write nested queries or queries containing common table expressions (CTEs), but for multi-step pipelines, queries written in this way can become overly complex and hard to reason through. Furthermore, it may not even be possible to use nested queries or CTEs to represent some use cases, in which case materializing the results and running multiple stream processing jobs is necessary.
To make stream processing simpler, more efficient, and more cost effective, we wanted to have the capability of combining multiple statements together. We did this by creating a new feature called Applications, which has the following benefits:
- Simplify the workload: Users can simplify a complex computation logic by dividing it into several statements without additional costs. This helps break down a complicated workload into multiple steps to improve readability of the computation logic and reusability of results. Smaller, distinct statements will also facilitate debugging by isolating the processing steps.
- Reduce the load on streaming Stores: An Application in DeltaStream optimizes I/O operations on streaming Stores in two ways. First, the Application will only read from a unique source Relation’s topic once. This reduces the read operations overhead when multiple queries in the Application consume records from the same Relation. Second, users can eliminate the reads/writes from intermediate queries by specifying “Virtual Relations” in the Application. “Virtual Streams” and “Virtual Changelogs” are similar to regular Streams and Changelogs in DeltaStream, but they are not backed by any physical streaming Store. Instead, Virtual Relations are for intermediate results and other statements in the Application are free to read/write to them.
- Reduce overall execution cost and latency: All statements in an Application run within a single runtime job. This not only reduces the overall execution cost by minimizing the total number of jobs needed for a workload, but also enhances resource utilization. Packing several statements together facilitates efficient resource sharing and lowers scheduling overhead for the shared resources. Additionally, the optimized I/O operations on streaming Stores (as previously mentioned) along with less network traffic from/to those Stores contribute to the overall cost and latency reduction.
Simplifying Data Workloads with Applications
Let’s go over an example to show how Applications can help users write a workload in a simpler and more efficient manner.
Assume we are managing an online retail store and we are interested in extracting insights on how users visit different pages on our website. There are two Kafka Stores/clusters, one in the US East region and one in the US West to store page views in each region. Registered users’ information is also stored separately in the US West Store. We have the following Relations defined on topics from these Stores:
- “pageviews_east” and “pageviews_west” are two Streams defined on the topics in the US East and US West stores, respectively
- “users_log” is a Changelog defined on the users’ information topic in the US west Store, using the “userid” column as the primary key
You can find more details about Stores, Streams and Changelogs in DeltaStream and how to create them here.
Our online advertisement team is curious to find out which product pages are popular as users are browsing the website. A page is popular if it is visited by at least 3 different female users from California in a short duration. Using the three Relations we defined above, we’ll introduce a solution to find popular pages without using an Application,then compare that with an approach that uses an Application.
“No Application” Solution
One way to find popular pages is by writing 4 separate queries:
- Query 1 & Query 2: Combine pageview records from the “pageviews_west” and “pageviews_east” Streams into a single relation. The resulting Stream is called “combined_pageviews”.
- Query 3: Join “combined_pageviews” records with records from “users_log” to enrich each pageviews record with its user’s latest information. The resulting Stream is called “enriched_pageviews”.
- Query 4: Group records in “enriched_pageviews” by their “pageid” column, aggregate their views, and find those pages that meet our popular page criteria.
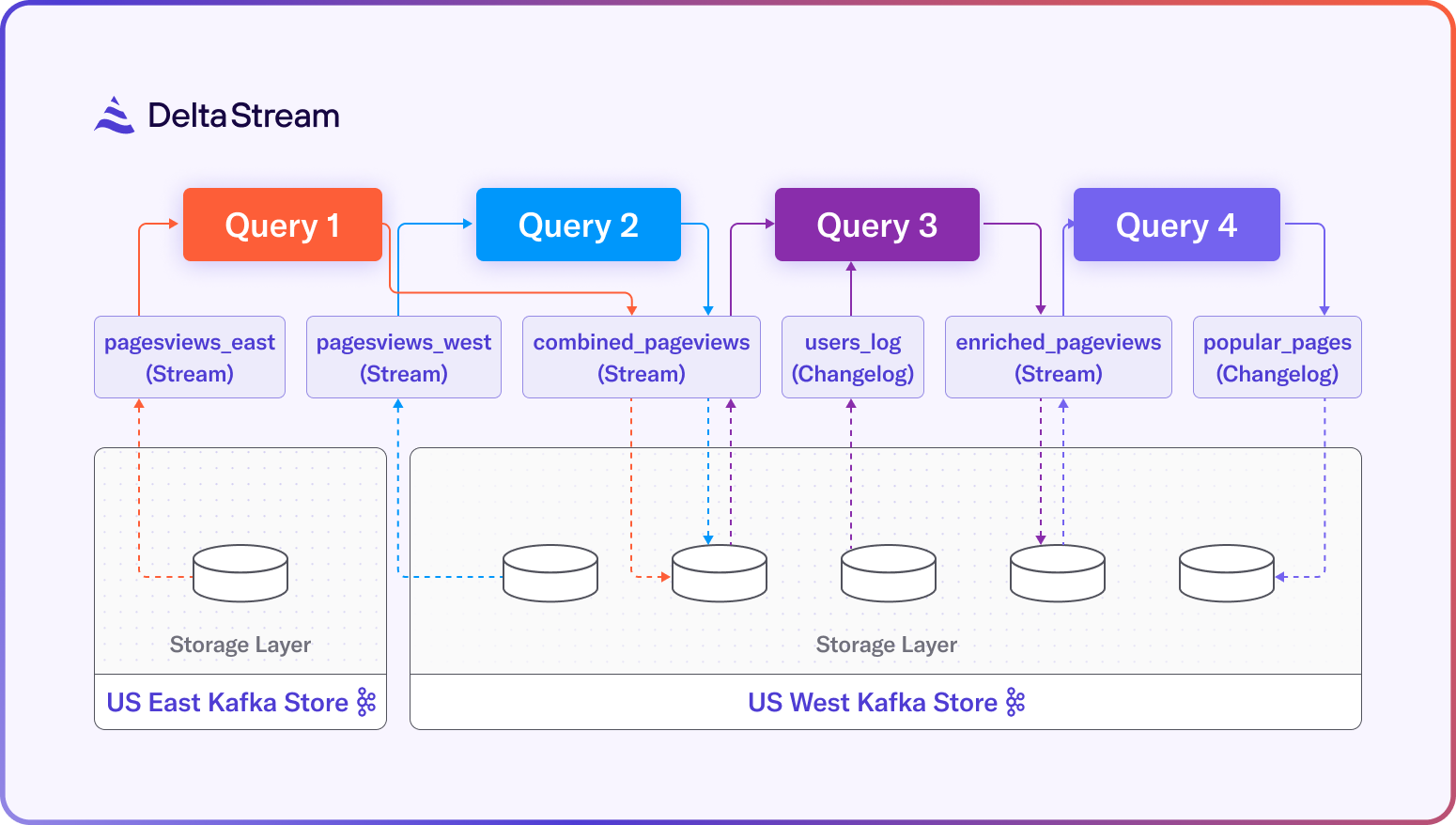
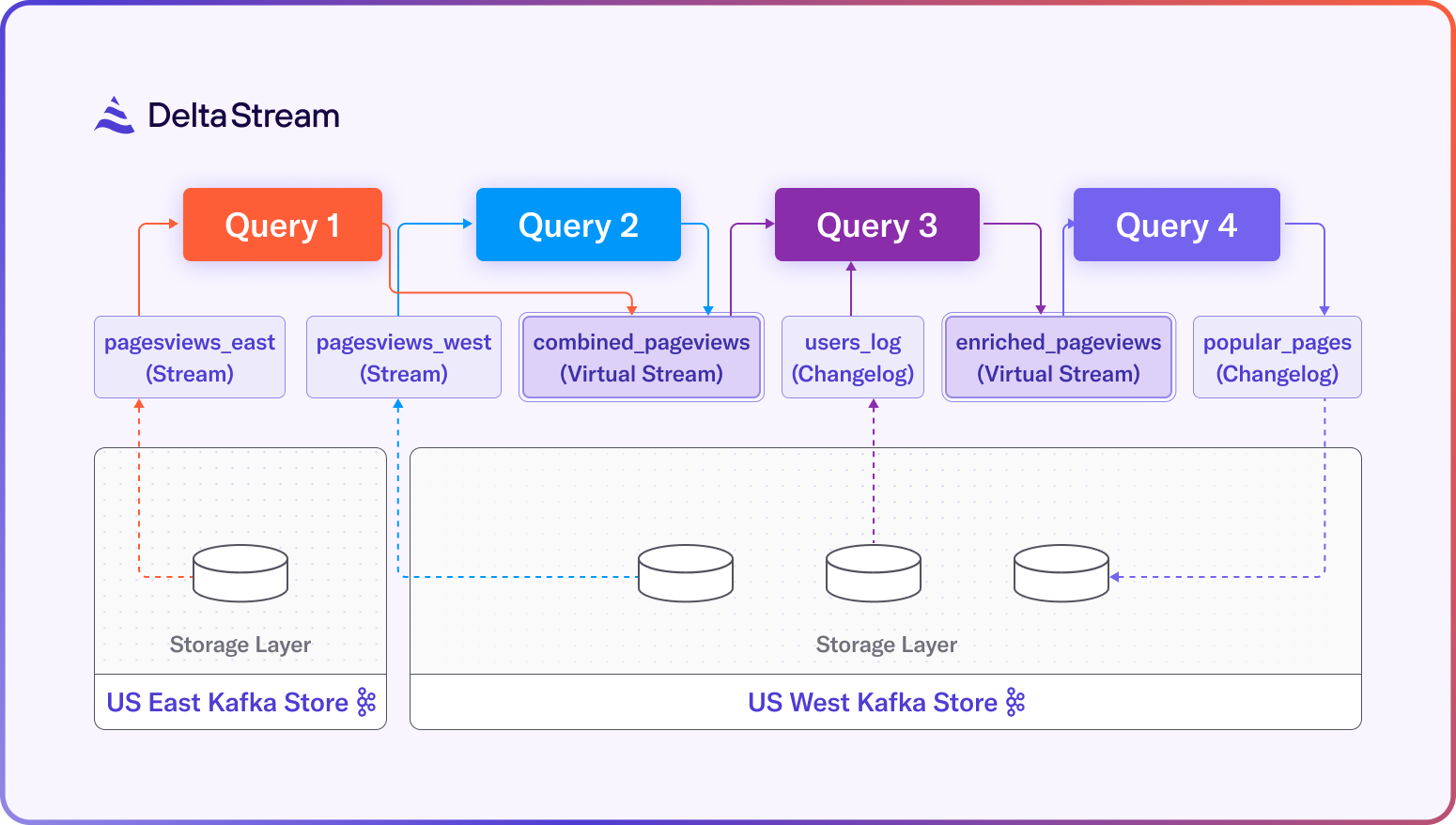
Figure 1 shows how the data flows between the different Relations (shown as rounded boxes) and the queries (shown as colored boxes). Each query results in a separate runtime job and requires its own dedicated resources to run. The dashed arrows between the Relations and the Stores indicate read and write operations against the Kafka topics backing each of the Relations. Moreover, given that each Relation is backed by a topic, all records are written into a persistent Store, including records in the “combined_pageviews” and “enriched_pageviews” Streams.
Solution with Application
Ideally, we are interested in reducing the cost of running our workload without modifying its computation logic. In the “No Application” solution above, while the records for “combined_pageviews” and “enriched_pageviews” are persisted, we don’t really need them outside the Application context. They are intermediate results, only computed to prepare the data for finding popular pages. “Virtual Relations” can help us skip materializing intermediate query results.
We can write an Application with Virtual Relations to find popular pages, as shown below. This Application creates a single long-running job and helps reduce costs in two ways:
- By using Virtual Relations, we can avoid the extra cost of writing intermediate results into a Store and reading them again. This will reduce the network traffic and the read/write load on our streaming Stores.
- By packing several queries into a single runtime job, we can use our available resources more efficiently. This will reduce the number of streaming jobs we end up creating in order to run our computation logic.
Here is the Application code for our example:
There are 4 statements in this Application. They look similar to the 4 queries used in the “no Application” solution above. However, the “combined_pageviews” and “enriched_pageviews” Streams are defined as Virtual Relations in the Application.
Figure 2 illustrates how the data flows between the different statements and Relations in the Application. Compared to Figure 1, note that the “combined_pageviews” and “enriched_pageviews” Virtual Streams (shown in white boxes) do not have dashed arrows leading to a Kafka topic in the storage layer. This is because Virtual Relations are not backed by physical storage, and thus reads and writes to the Store for these Virtual Relations are eliminated, reducing I/O and storage costs. In addition, the 4 queries in Figure 1 generate 4 separate streaming jobs, whereas all processing happens within a single runtime job in the solution using an Application.
Platform for Efficient Stream Processing
In this blog, we compared two solutions for a stream processing use case, one with an Application and one without. We showed how Applications and Virtual Relations can be used to run workloads more efficiently, resulting in reduced costs. The SQL syntax for Application helps users simplify their complex computation logic by breaking it into several statements, and allows reusing intermediate results with no additional cost. Stay tuned for more content on Application in the future, where we’ll dive more deeply into the individual benefits of running Applications and include more detailed examples.
DeltaStream is easy to use, easy to operate, and scales automatically. If you are ready to try a modern stream processing solution, you can reach out to our team to schedule a demo or start your free trial.